
In my previous blog post about the C Tool Chain, I mentioned a post about configuring the C compiler, which is what this blog will discuss. Please note that I will not be talking about linkers or linking, just compiling. Configuring linkers may be a future blog post.
Most C programs need similar information to build. So when starting a new project with a new compiler there are a few things you can expect every C compiler to do. For example, you may have noticed in your code a ‘#include “somefile.h”’ floating around at the top. Well how does the C compiler know where somefile.h is? Long story short; if it’s not in the same directory as the current file, or in any of the standard library folders, then the C compiler does not know where that file is. This will result in the build failing. You will need to configure the compiler’s “Include Directories”
What does configuring “Include Directories” look like?, I hear you ask. It is different depending on what compiler you are using. Below are command line examples for the gcc and cl compilers to build ‘filetobuild.c’.

Notes:
• The –c on the gcc build and the /c on the cl build stop the compiler from automatically linking.
• Gcc uses lowercase ‘L’ and cl uses upper case ‘I’.
Moving on, have you ever seen what looks like a pre-processor constant being used without #define in sight? Well, that is because it is defined as a compiler configuration. I will show examples below for gcc and cl to define CONFIG1 without assignment and CONFIG2 as 5:

Next up – debugging and optimization. Most people (myself included) write really inefficient code from the perspective of the computer. This is a good thing though. Most of the time we do this to make the code more readable, at least from a human perspective. Also, one computer’s opinion of efficient code can be completely different from another computer’s opinion. This is where compiler optimization comes in. You can tell your compiler to optimize your code. This results in slightly longer build time as the compiler is trying to rework your code into something the target CPU can run faster. Optimization can have different levels from “don’t mess with what I wrote” to “make this run as fast as you can, you can change whatever you want”. You generally want to turn up the optimizations on a release build so you can get the end user the fastest version of the program.
Let us switch over to debugging. Your compiled C file does not have enough information on its own for the debugger to show you what is in some variable. So, the compiler will need to produce special output to give the debugger the information it needs.
Debugging and Optimization conflict with each other. If the optimizer decided to swap the order of some of your code, the debugger will be very confused about what is going on in the code because it is assuming unoptimized code order. If the compiler is instructed to produce debug symbols and optimized code at the same time, it will either, not optimize, not produce debug symbols, or produce an error.
Let’s look at an optimization example for both gcc and cl at max optimization:

Let’s look at a debugging example for both gcc and cl:

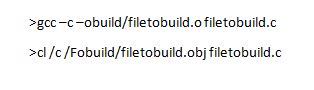
That covers the debugging and optimization. The last command that gets used often is setting the output file path and name. This is done with the following on cl and gcc where we put the result in the ‘build’ folder:
Finally, we have a good idea of what all these options do. We can now put them all together to build the program that we want:

Now you have a good idea of what these large commands are actually doing. I want to say that I don’t have this all memorized myself. I had to look some of this up on the internet. It takes time to learn all the details of a particular compiler. I don’t normally perform builds by the command line. I rely on a build system like make, Visual Studio, or my personal favorite, bam to make that happen. You also should be aware that compilers change over time and new compilers may change the commands shown above. Happy compiling!